Caractérisation acoustique des phonèmes#
Nous sommes constamment exposé·es à des sons de parole, que notre cerveau comprend quasi-instantanément et sans effort apparent. Le processus semble aller de soi, à tel point qu’il est difficile a priori d’imaginer que ce mécanisme de décodage puisse faire l’objet de recherches approfondies depuis maintenant plus d’un siècle. Ne suffit-il pas au cerveau de mémoriser l’association entre chaque phonème et le son qui lui correspond, comme on déchiffre un message en Morse en consultant le tableau de correspondance (l’alphabet Morse) ? Pour le dire crûment : si nous entendons le son “b” nous en déduisons qu’il s’agit de la consonne [b], si nous entendons le son “a” nous en déduisons qu’il s’agit de la voyelle [a], qu’y a-t-il de sorcier là-dedans ? Bref, si chaque consonne et chaque voyelle est associée à un son particulier et spécifique, imaginer un mécanisme de décodage est assez aisé. Dans cette section, nous examinerons en détail les propriétés acoustiques des sons de parole pour tenter d’établir les grandes lignes de cet “alphabet acoustico-phonétique”. Cette exploration nous amènera à identifier les écueils auxquels se trouve confrontée cette explication intuitive.
Qu’est-ce qu’un phonème ?#
Avant d’étudier les caractéristiques acoustiques des phonèmes, il est essentiel de clarifier ce que l’on entend par ce terme. À la suite des travaux fondateurs du Cercle de Prague au début du XXe siècle, les linguistes définissent le phonème comme le plus petit élément porteur de sens dans le son de parole, c’est-à-dire en quelque sorte comme l’ “atome”, ou la “brique de base”, du langage parlé.
Quels sont exactement les rapports entre les sons et le sens à l’intérieur du mot et de la langue en général ? Finalement, il s’agit de dégager le plus petit élément phonique chargé d’une valeur significative, ou – en termes métaphoriques – il s’agit de trouver les quanta de la langue. (Jakobson, Six leçons sur le son et le sens, 1973)
Jakobson et les autres linguistes du Cercle de Prague ne proposent pas seulement une définition théorique du phonème, mais également une méthode pratique pour recenser l’ensemble des phonèmes d’une langue donnée. Elle consiste à identifier des paires minimales : des couples de mots différant par un son unique. Ainsi, en français, les mots “bagage” et “bagarre” ont des sens radicalement distincts, pourtant seul leur tout dernier son, “j” ou “r”, est différent. Cette paire suffit à prouver que, dans notre langue, l’opposition “j”-“r” est porteuse de sens, et donc que “j” et “r” constituent deux phonèmes distincts. De la même façon, “malle” et “mille” forment une paire minimale en français, séparée uniquement par les phonèmes “a” et “i”.
En appliquant cette approche de façon systématique, il devient possible de dresser l’inventaire des phonèmes d’une langue donnée, et par extension d’établir une typologie des systèmes phonologiques du monde entier. Ce travail méticuleux est compilé dans les tables de l’alphabet phonétique international (International Phonetic Alphabet, IPA) [1]. De même qu’on parle métaphoriquement du phonème comme l’atome dont sont composés tous les sons parlés, on pourrait faire l’analogie entre le tableau de l’IPA et le célèbre système des éléments chimiques établi par Mendeleev.
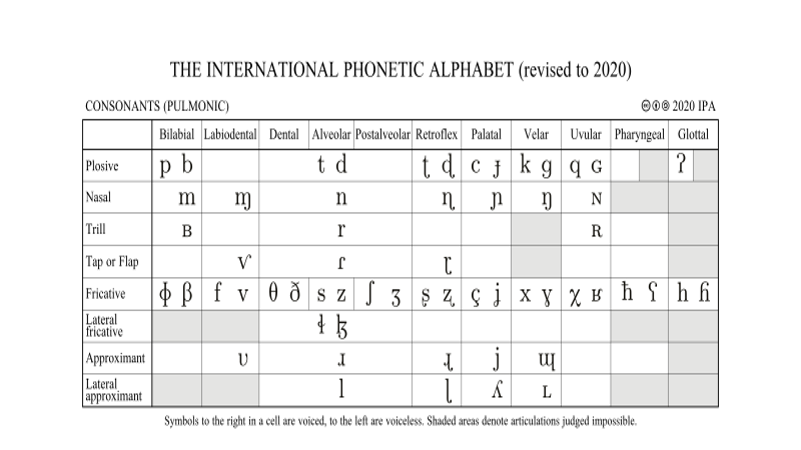
Fig. 86 Le tableau de l’Alphabet Phonétique International, présentant les principales consonnes et voyelles des différentes langues du mondes. (source: www.internationalphoneticassociation.org)#
Cette définition phonologique, bien qu’indispensable, demeure néanmoins relativement éloignée du niveau acoustique des sons de parole. Comme le souligne Ferdinand de Saussure, la phonologie considère le phonème comme une unité abstraite, dont l’association avec un son concret particulier est purement contingente et arbitraire. Autrement dit, les phonèmes sont définis ici avant tout par leur fonction (celle de structurer les mots) plutôt que par leurs caractéristiques acoustiques. On pourrait les comparer aux pièces d’un jeu d’échecs, qu’il est possible de remplacer par n’importe quels autres objets pourvu que les joueur·euses se mettent d’accord sur leur rôle dans le jeu.
Cette approche laisse donc en suspens les questions qui nous préoccupent dans ce chapitre : quelles sont les caractéristiques acoustiques qui permettent de distinguer un phonème d’un autre ? Comment le cerveau interprète-t-il ces signaux pour en extraire du sens ? Pour y répondre, il est nécessaire d’examiner de plus près la forme acoustique des phonèmes.
Les voyelles#
Pour découvrir les signatures sonores des phonèmes, une approche assez intuitive consiste à examiner des enregistrements de parole afin d’y repérer des régularités. C’est le programme de la phonétique acoustique.
La figure ci-dessous présente les spectrogrammes de trois voyelles du français : “i”, “a” et “ou”. Deux enregistrements de chaque voyelle sont présentés, ce qui permet de remarquer une caractéristique frappante : la présences de bandes d’énergies relativement stables dans le temps, et dont les fréquences semblent dépendre de la voyelle prononcée. Ces maxima spectraux, appelés formants, sont numérotés des basses vers les hautes fréquences : le premier formant (F1) est le plus grave, suivi du deuxième (F2), et ainsi de suite. Notez que les spectrogrammes présentent également des raies verticales régulièrement espacées, reflétant la hauteur de la voix (appelée fréquence fondamentale). Ces raies sont relativement indépendantes des formants et ne jouent pas de rôle direct dans la compréhension des voyelles.
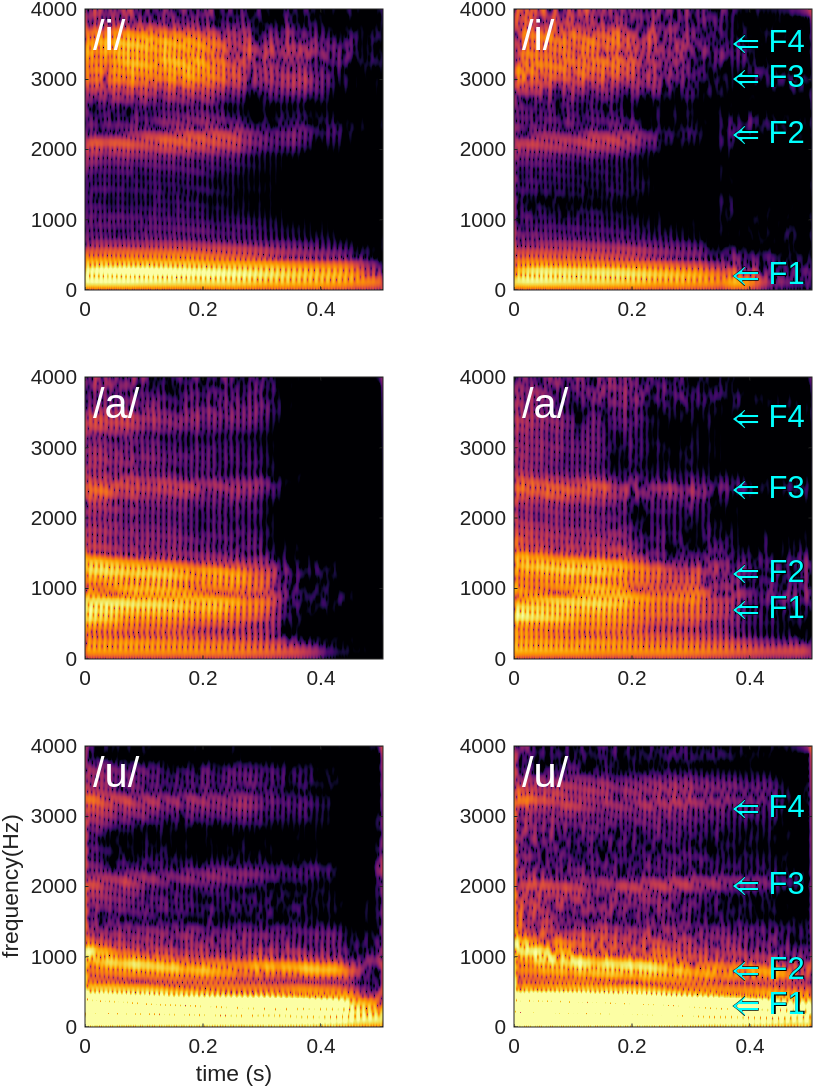
Fig. 87 Spectrogrammes de 3 voyelles du français : “i”, “a” et “ou”. Deux enregistrements de chaque voyelle sont présentés, et les positions des quatre premiers formants (F1, F2, F3 et F4) sont indiqués par des flèches.#
L’origine physique des formants est directement liée à la structure anatomique de l’appareil phonatoire, et plus précisément à la configuration de la bouche du locuteur ou de la locutrice. Lorsque nous parlons, l’air en provenance des poumons traverse notre larynx, mettant en vibration les cordes vocales, puis progresse jusque dans notre cavité buccale. Cette cavité agit comme un résonateur naturel, dont les propriétés acoustiques dépendent de sa forme et de ses dimensions à un instant donné. Mettre en mouvement nos articulateurs – langue, lèvres, palais et mâchoire – permet de modifier cette configuration et, par conséquent, les fréquences de résonance produites. La figure suivante illustre ce lien entre la forme de la cavité buccale et les fréquences des formants. Chaque voyelle correspond à une position spécifique des articulateurs, modifiant ainsi la “caisse de résonance” que forme la bouche. Lorsque la langue se soulève et que les lèvres s’avancent pour produire la voyelle “ou”, la cavité buccale se rétrécit et s’allonge, ce qui produit des fréquences de résonance plutôt graves (F1 = 400 Hz, F2 = 900 Hz). À l’inverse, pour un son comme “a”, la bouche s’ouvre largement, créant une cavité plus grande et plus uniforme, qui favorise des résonances différentes (F1 = 800 Hz, F2 = 1400 Hz).
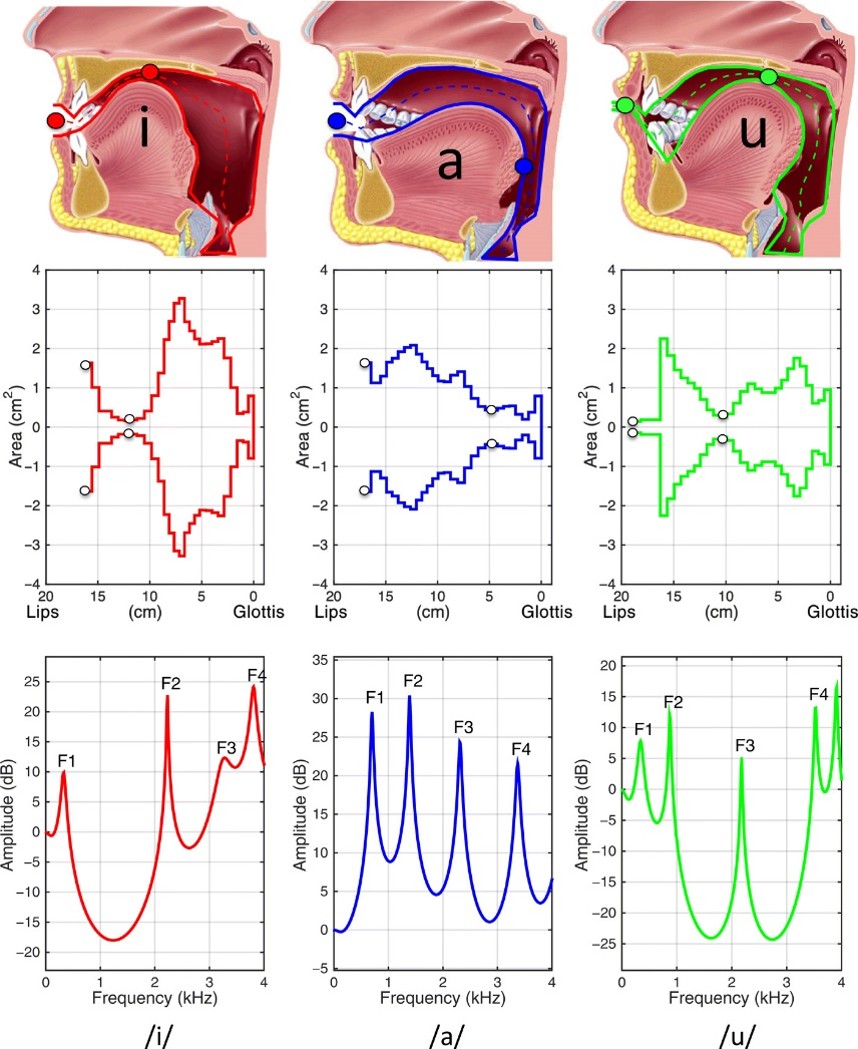
Fig. 88 Illustration du lien entre forme de la cavité buccale et fréquence des formants. La ligne supérieure schématise les positions des articulateurs correspondant à trois voyelles. En dessous est représentée la forme de la “caisse de résonance” ainsi formée, depuis la gorge jusqu’aux levres. Enfin, la dernière ligne présente le spectre des résonances produites par cette cavité (obtenues par simulation informatique). Ces spectres présentent des pics très marqués, correspondant aux formants. Figure issue de Boë et al. (2019)#
Chaque configuration des articulateurs produit ainsi un filtre acoustique particulier, amplifiant certaines fréquences (les formants) tout en en atténuant d’autres. le premier formant (F1) est généralement lié au degré d’ouverture de la bouche, tandis que le second (F2) est principalement influencé par la position antérieure ou postérieure de la langue. Ainsi, de subtiles variations dans la position des articulateurs se traduisent par des différences perceptibles dans les sons de parole. Pour illustrer l’importance des résonances formantiques, la vidéo ci-dessous présente une expérience dans laquelle des tubes ont été conçus pour imiter la forme de la cavité buccale associée à différentes voyelles. Un buzzer est placé à l’entrée de chaque tube, de façon à faire résonner le son à travers le tube. À l’autre extrémité, on entend clairement la voyelle correspondant à la forme de la cavité, démontrant que les résonances constituent un élément crucial de l’identité de la voyelle.
Ainsi, le son des phonèmes est-il une “empreinte” acoustique de la position de la langue, des lèvres, du palais et de la mâchoire. En quelque sorte, le langage parlé peut être comparé à une langue des signes invisible : les gestes ne sont pas exécutés par les mains mais par les articulateurs de la bouche, et ces derniers n’étant pas directement visibles à l’œil de l’interlocuteur·ice, ils doivent être rendus audibles par le phénomène de résonance, transformant des mouvements articulatoires en signaux sonores.
Des experiences en synthèse vocale suggèrent que les deux premiers formants sont suffisants pour identifier les voyelles, même lorsque les formants 3 et 4 sont fixés à des valeurs intermédiaires. Cette observation a conduit les scientifiques à représenter les voyelles dans un espace à deux dimensions, appelé triangle vocalique ou espace vocalique (vowel space), où chaque axe correspond aux fréquences de F1 et F2. La figure ci-dessous présente les résultats d’une étude menée par Hillenbrand et ses collègues (1995), qui ont enregistré un grand nombre de productions de la voyelle “è” par différents locuteurs et locutrices anglophones. Pour chaque enregistrement, les valeurs de F1 et de F2 ont été mesurées et reportées sur un graphe. Chaque point (indiqué par le symbole æ) représente un enregistrement particulier de la voyelle, avec les valeurs de F2 et de F1 en x et en y, respectivement.
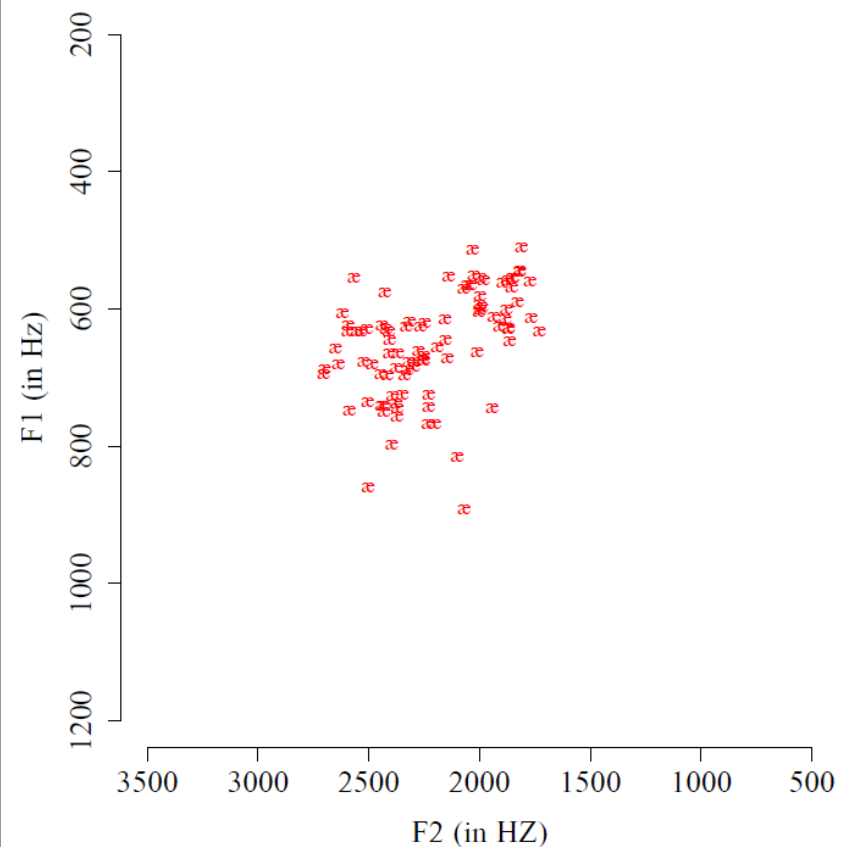
Fig. 89 Répartition des valeurs de F1 et F2 pour différentes réalisations de la voyelle “è” par des locuteurs et locutrices anglophones. Chaque point correspond à un enregistrement spécifique. (Adapté de Hillenbrand et al., 1995).#
Comme attendu d’après nos premières observations (Fig. 87), les fréquences des formants F1 et F2 pour différentes réalisations d’une même voyelle (ici “è”) sont très similaires (environ 700 Hz pour F1 et 2200 Hz pour F2), bien qu’elles présentent une certaine variabilité. Cette dispersion reflète l’impossibilité pour l’appareil phonatoire humain de produire un son strictement identique à plusieurs reprises. Néanmoins, la concentration des points autour de valeurs centrales confirme que les formants sont une propriété déterminante de l’identité des voyelles.
En répétant cette analyse pour les voyelles “a”, “i” et “ou”, on obtient une répartition caractéristique dans l’espace vocalique, comme illustré ci-dessous.
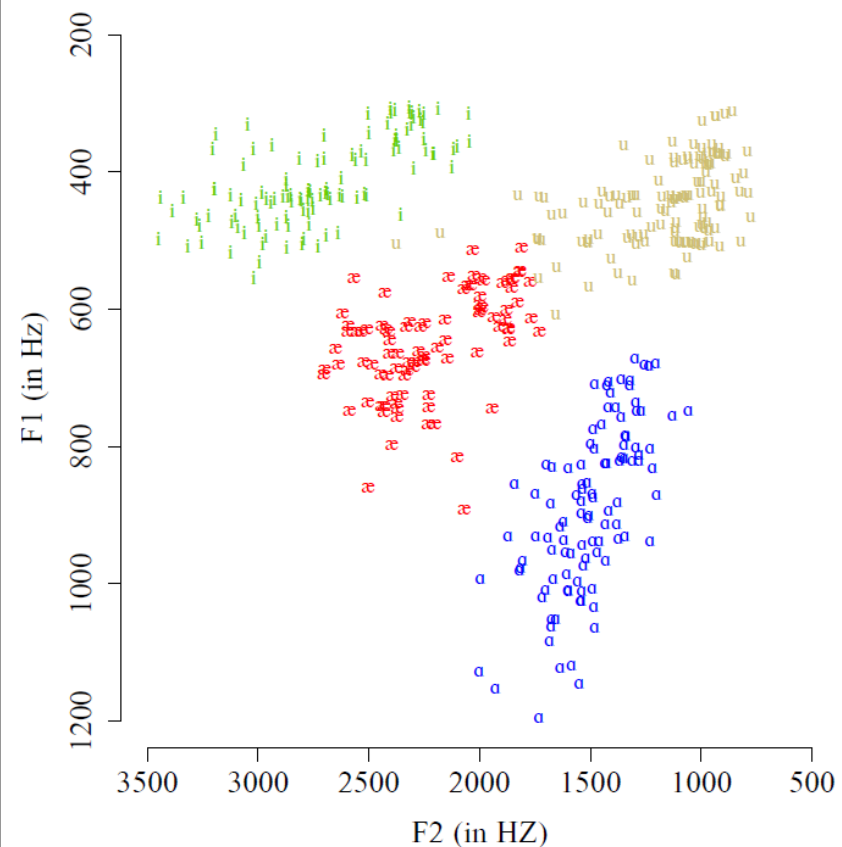
Fig. 90 Répartition des voyelles “è”, “a”, “i” et “ou” dans l’espace vocalique défini par F1 et F2. Chaque couleur correspond à une voyelle distincte.#
On constate que les voyelles se répartissent dans l’espace vocalique – ce qui est, là encore, cohérent avec l’idée que chaque voyelle est définie par ses valeurs de F1 et F2.
Cette représentation met en évidence un premier problème théorique posé par la compréhension des phonèmes : le problème de la discrétisation. Le cerveau doit subdiviser un espace acoustique continu, où une infinité de sons est possible, en un nombre fini de catégories distinctes, chacune associée à un phonème. Autrement dit, une information acoustique initialement très détaillée (comme les valeurs exactes de F1 et F2) est réduite à une représentation discrète et opérationnelle (le phonème correspondant). Comme nous le verrons plus loin, ce processus de discrétisation évacue une information non pertinente pour la compréhension (le détail des valeurs des formants) pour ne garder que l’information cruciale, l’identité du phonème entendu.
Schématiquement, résoudre le problème de la discrétisation revient à placer des frontières (les frontières phonémiques) dans l’espace acoustique pour délimiter les régions correspondant à chaque voyelle, comme illustré sur la figure suivante. Lorsque nous percevons un son de voyelle, il suffirait alors à notre cerveau de mesurer les valeurs de F1 et F2 et de déterminer dans quelle région de l’espace vocalique se situe ce son [2].
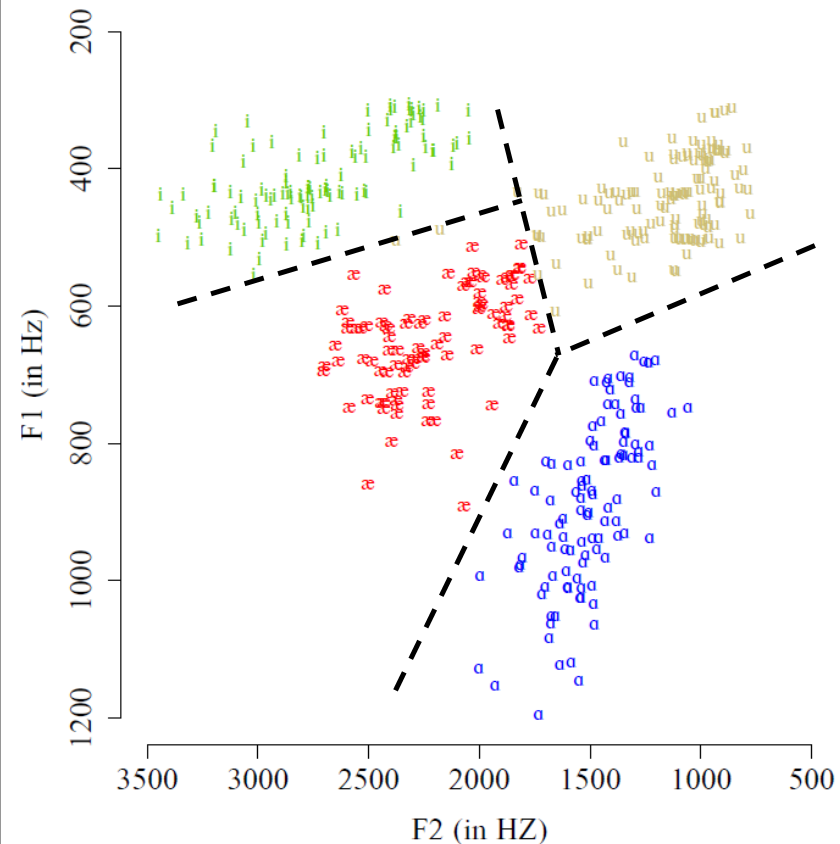
Fig. 91 Exemple de frontières phonémiques hypothétiques dans l’espace F1-F2, délimitant les régions associées à chaque voyelle.#
Malheureusement, cette solution se heurte à un second problème. En continuant à remplir l’espace vocalique avec l’ensemble des voyelles de l’anglais, nous constatons rapidement que celles-ci se recouvrent dans une large mesure. Ainsi, par exemple, la région de l’espace F1-F2 correspondant à la voyelle [ɪ] (comme dans “kit”) est entièrement superposée à celles des voyelles [i] (comme dans “happy”) et [e] (comme dans “dress”). Autrement dit, pour un grand nombre de sons (c’est-à-dire de points sur la figure), il est impossible d’identifier la voyelle de façon univoque, c’est-à-dire de déterminer avec certitude, sur la base de F1 et F2, s’il s’agit d’une voyelle plutôt que d’une autre.
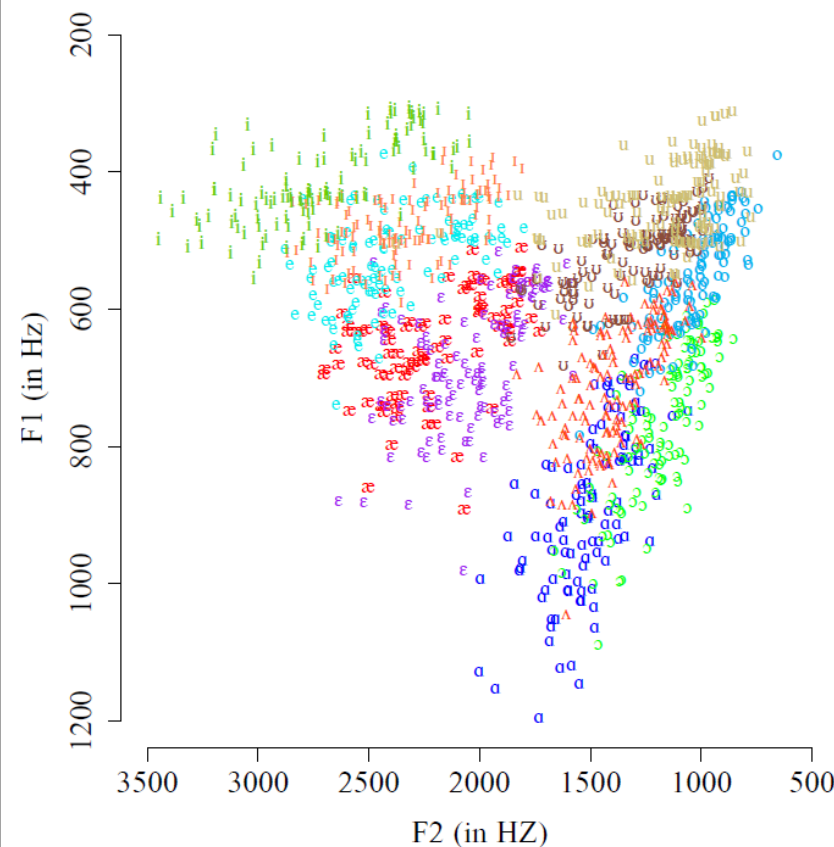
Fig. 92 Répartition de toutes les voyelles de l’anglais dans l’espace vocalique défini par F1 et F2. Chaque couleur correspond à une voyelle distincte.#
Ce second problème est appelé problème du manque d’invariance (lack-of-invariance problem) : la variabilité dans le signal de parole semble à première vue trop grande pour permettre au cerveau de décoder les phonèmes de manière robuste. Le très large recouvrement entre les régions correspondant aux différentes voyelles semble en contradiction avec notre grande facilité à différencier une voyelle d’une autre.
Les consonnes#
Le tableau n’apparaît pas moins complexe du côté des consonnes. La figure suivante représente les spectrogrammes de 12 sons “aXa”, où X représente l’une des consonnes suivantes : “b”, “d”, “g”, “p”, “t”, “k”, “f”, “s”, “ch”, “m”, “n” et “l”.
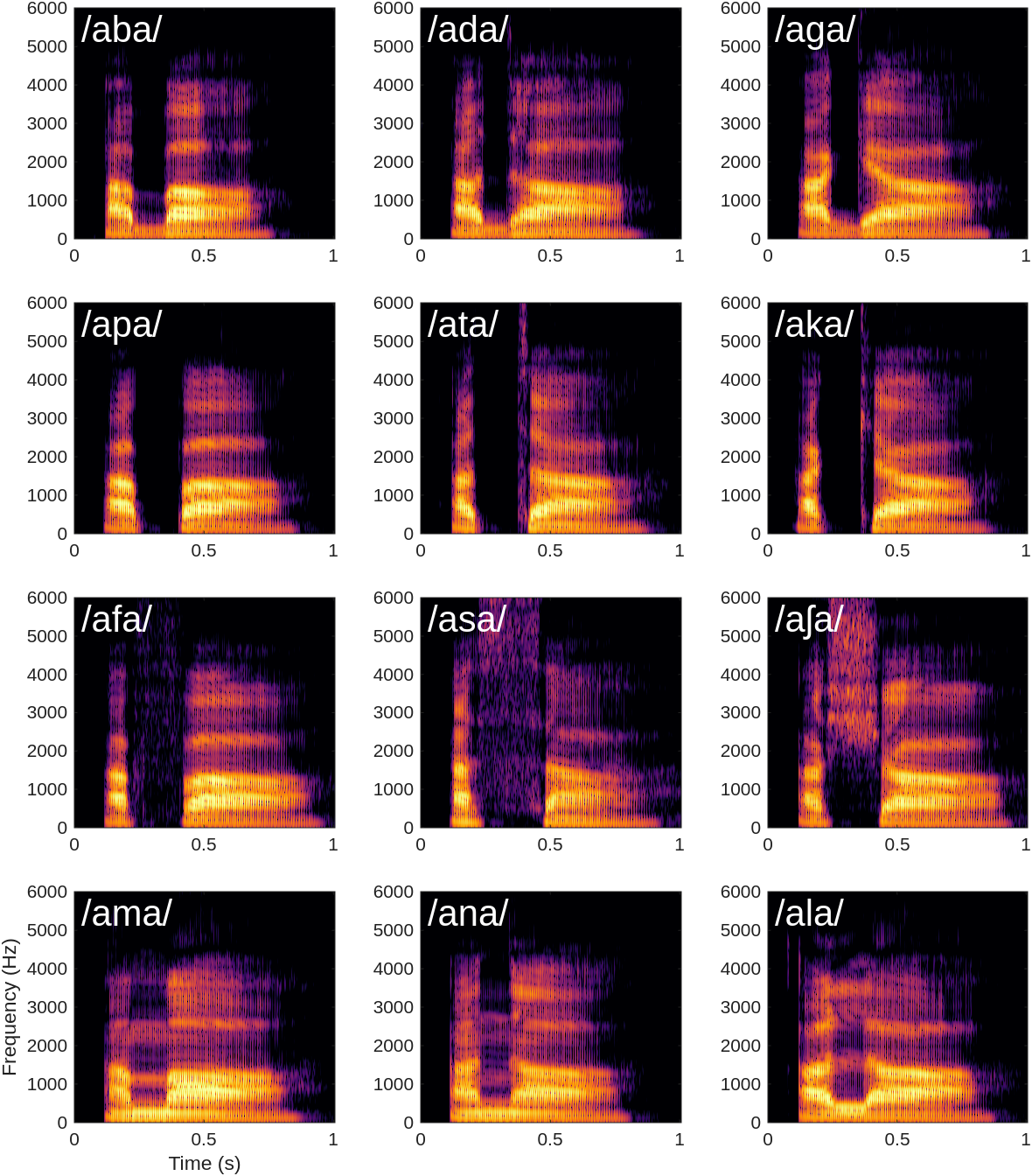
Fig. 93 Spectrogrammes de 12 consonnes du français, précédées et suivies d’un “a” : “aba”, “ada”, “aga”, “apa”, “ata”, “aka”, “afa”, “asa”, “acha”, “ama”, “ana” et “ala”.#
Contrairement aux voyelles, principalement caractérisées par les positions de leurs formants, les consonnes présentent une diversité de motifs sonores bien plus complexes. Dans chaque spectrogramme, les deux “a” sont clairement reconnaissables par la présence de formants horizontaux à des valeurs relativement stables. L’intervalle entre les deux, correspondant à la consonne, révèle des motifs très différents d’un son à l’autre. Ces disparités acoustiques entre consonnes reflètent directement la diversité des gestes articulatoires mis en œuvre pour les produire :
les consonnes plosives, que nous explorerons plus en détail dans la suite de ce chapitre, sont produites en interrompant momentanément le flux d’air, par exemple en joignant les lèvres pour “p” ou “b”. Cette occlusion engendre un bref silence dans le son de parole, visible sous la forme d’un intervalle vide entre les deux voyelles “a” sur les spectrogrammes de “aba”, “ada”, “aga”, “apa”, “ata” et “aka”.
les consonnes fricatives nécessitent de laisser passer seulement un filet d’air turbulent, par exemple en rapprochant la langue du palais pour “s” ou “ch”. Ce phénomène produit un bruit de friction, visible comme une zone d’énergie couvrant une large bande de fréquences sur les spectrogrammes de “afa”, “asa”, et “acha”.
enfin, les consonnes liquides (comme “l”) ou nasales (comme “m”, “n”), fonctionnent essentiellement sur le même principe de résonances dans la cavité buccale (et nasale) que les voyelles. C’est pourquoi leur spectrogramme présente également des formants à des fréquences précises, mais d’intensité plus faible.
On retrouve pour les consonnes les mêmes problèmes de la discrétisation et du manque d’invariance rencontrés précédemment avec les voyelles. Ainsi, il semble difficile d’associer un son particulier à une consonne plosive de façon univoque. Considérons de plus près les spectrogrammes des deux consonnes plosives “d” et “t”, précédées et suivies soit de “i”, de “a”, ou de “ou” (figure suivante). On s’aperçoit rapidement que la forme acoustique des consonnes dépend considérablement du contexte, à tel point que le “d” de “idi” ressemble plus au “t” de “iti” qu’à un autre “d” dans “ada” ou “oudou”. Autrement dit, des sons acoustiquement proches peuvent correspondre à des phonèmes distincts, illustrant ainsi le problème du manque d’invariance.
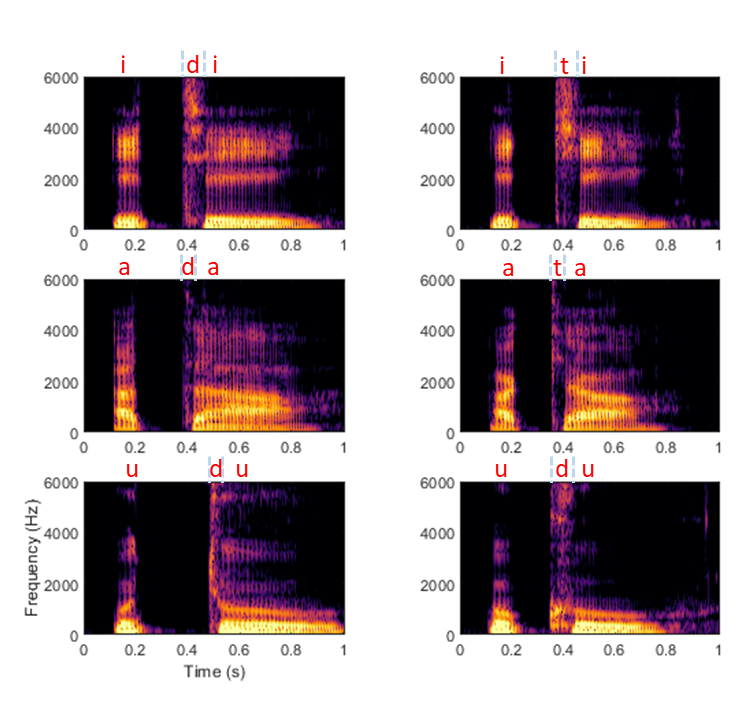
Fig. 94 Spectrogrammes des consonnes “d” et “t”, en contexte “a”, “i” ou “ou”.#
À l’inverse, des sons acoustiquement très différents peuvent être perçus comme un seul et même phonème. La figure suivante présente à nouveau les spectrogrammes de “idi”, “ada” et “oudou”, en mettant en avant en bleu les trajectoires des premier et deuxième formants. Dans chaque cas, les deux formants convergent vers les valeurs stables correspondant aux voyelles “a”, “i” et “ou”, respectivement. Cependant, la partie initiale, qui traduit dans les trois sons la consonne “d”, varie radicalement : l’attaque du second formant est fortement ascendante dans le cas de “idi”, légèrement ascendante dans le cas de “ada”, et descendante dans le cas de “oudou”. La raison de cette variabilité est la coarticulation, sur laquelle nous reviendrons en détail plus loin : le mouvement de la langue nécessaire à la production du “d” se superpose aux commandes articulatoires préparant le phonème qui suit. Ainsi, le “d” n’existe pas acoustiquement comme une entité isolée : son identité dépend du contexte vocalique qui le suit. Concrètement, la coarticulation souligne à nouveau le problème de la discrétisation, déjà évoqué dans le cas des voyelles : pour comprendre la parole, le cerveau doit catégoriser sous une même étiquette des sons parfois radicalement distincts.
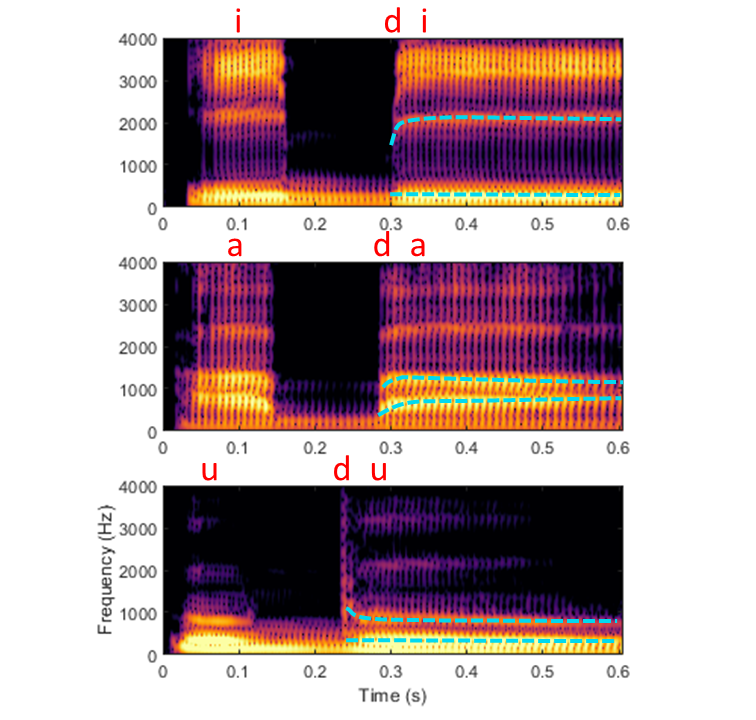
Fig. 95 Spectrogrammes des sons “ada”, “idi” et “oudou”. Les lignes pointillées bleues représentent les trajectoires des formants F1 et F2 au cours de la deuxième syllabe.#
La compréhension des phonèmes repose sur une illusion perceptuelle : Des sons acoustiquement très différents sont perçus de manière identique, tandis que des sons similaires peuvent être interprétés différemment. Ce caractère illusoire est d’autant plus évident lorsque l’on considère notre capacité à identifier des phonèmes dans une langue étrangère. En l’absence de familiarité avec les règles phonétiques de la langue, notre système perceptif peine à catégoriser correctement les sons. Notre perception des sons de parole ne reflète donc pas seulement leurs propriétés acoustiques ; elle est le résultat d’un traitement cognitif complexe, ancré dans l’expérience et les attentes de l’auditeur·rice.
Conclusions temporaires#
Nous avons entamé cette section avec pour objectif d’établir une table de conversion acoustico-phonetique, fondée sur l’hypothèse d’une correspondance systématique entre spectrogrammes et phonèmes. En effet, si les phonèmes présentaient des signatures acoustiques invariables, reproduites de manière systématique par les locuteurs et locutrices lorsqu’ils et elles prononcent ces phonèmes, il serait alors relativement aisé d’expliquer la capacité du cerveau humain à identifier et catégoriser ces sons de façon robuste.
Au travers de cette exploration, nous avons identifié que les formants constituent un élément très important pour l’identité des voyelles et, dans une certaine mesure, des consonnes. Cependant, notre analyse a également révélé deux écueils théoriques majeurs, remettant en cause notre projet initial. Premièrement, des réalisations acoustiques parfois très distinctes peuvent être perçues comme un seul et même phonème (problème de discrétisation). Deuxièmement, des sons partageant des caractéristiques acoustiques similaires peuvent être interprétés comme des phonèmes différents, notamment en fonction du contexte (problème du manque d’invariance). Ces observations soulèvent des questions fondamentales sur la possibilité d’établir une correspondance univoque entre les sons de parole et les unités phonémiques. Elles invitent donc à repenser notre modèle simpliste de la perception de la parole : il semble impossible que le cerveau stocke simplement en mémoire des “prototypes” des différents phonèmes et s’en serve pour identifier les sons qui lui parviennent.
Face à cette impasse, la phonétique acoustique atteint ses limites. Seule l’expérimentation psychoacoustique peut nous permettre d’éclairer les mécanismes de la compréhension de la parole par le cerveau.
Notes#
[1] Notez que cette présentation sous forme de table plutôt que de simple liste suggère une organisation particulière des phonèmes entre eux. Bien que cette perspective dite “structuraliste” – car elle met en lumière la structure des relations entre les phonèmes – soit fondamentale en phonologie, nous ne la détaillerons pas dans ce chapitre par souci de concision.
[2] D’autres mécanismes de catégorisation sont néanmoins envisageables, par exemple en calculant la distance du son perçu au centre de chaque catégorie.
Références#
Boë, L.-J., Sawallis, T. R., Fagot, J., Badin, P., Barbier, G., Captier, G., Ménard, L., Heim, J.-L., & Schwartz, J.-L. (2019). Which way to the dawn of speech? : Reanalyzing half a century of debates and data in light of speech science. Science Advances, 5(12), eaaw3916. https://doi.org/10.1126/sciadv.aaw3916
Hillenbrand, J., Getty, L. A., Clark, M. J., & Wheeler, K. (1995). Acoustic characteristics of American English vowels. The Journal of the Acoustical Society of America, 97(5 Pt 1), 3099‑3111.
Jakobson, R. (1973). Six leçons sur le son et le sens. Éditions de Minuit.